Hi welcome to my page I am Prakhar Pandey. I am a Data Scientist at Teradata. I completed my masters in Computer Science at UCSD. I finished my bachelors in Computer Science from IIT Roorkee. Himalayas are my second abode, they have mesmerised me ever since I came to my undergrad college. I also swim (like in summers for two months) , but the two things that you can be sure about me is, first my love for mountains and second my passion for reading. You can find me reading almost at any time, anywhere.
I have been studying Machine Learning for a while now, I am interested in its application in field of Natural Language Processing, Information Retrieval and Cognitive Sciences.I have also explored Deep Learning and was immediately impressed by the applications of word embeddings in classical NLP tasks. One of the other fields I am interested in is analysis of social network and how they effect decisions of the individuals who are part of it. My goal is to build an intelligent system which can capture the entire spectrum of emotions which are conveyed by a single line, gesture, or spoken words.
The entire basis of this project is the EEG signals which are electroencephalograms or saying in layman language the Brain Signals. The motivation behind using these signals is BCI the Brain Computer Interface where we try to guess the state of the brain or the intent of the person using just the EEG signals collected through the EMOTIV Epoc+ device.
EEG Signals
Electroencephalography (EEG) is an electrophysiological monitoring method to record electrical activity of the brain. It is typically noninvasive, with the electrodes placed along the scalp, although invasive electrodes are sometimes used in specific applications. There are four types of brain waves of interests based upon their frequency:
Delta (<4 Hz)
Theta (4-7 Hz)
Alpha (8-15 Hz)
Beta (16-31 Hz)
Word Familiarity
This is the task where we try to find out whether or not a subject is familiar with the given word using just the EEG signals.
We make use of Brain Activation Maps which are derived from the EEG Signals.
We collected samples from 13 subjects in which they were shown a list of 25 words and they were supposed to tell whether or not they knew the meaning.The recording of one of the subject was of no use because of too much noise and hence was discarded.
For each subject we get approximately 105 seconds of brain activation map video corresponding to each of the alpha and theta bands.
All the 105 seconds videos are converted to 64 X 64 pixel frames and these frames are then divided into 25 different subset of frames. These subsets represent a single instance of data and these are further divided into 7 parts. All the frames in these parts are aggregated into a single image. So, a group of 7 such images corresponds to single instance of data.
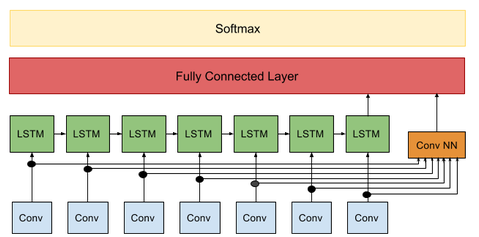
Model Architecture
The entire architecture is given according to the paper in paper
Each instance is approximately 4 secs long we divide this into 7 sections as described in paper. We extract the inter and intra subject behaviours with the help of CNNs and the information stored in the time domains with the help of LSTMs as shown in the picture above.
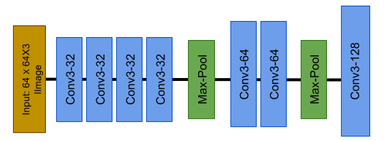
It takes as input 3-channel images of size 64X64, and is passed to 4 subsequent convolutional layer each of which have 32 filters of 3X3 dimension followed by a 2X2 maxpool layer which reduces width and height to half the original width and height of image. Reduced images are further passed to two subsequent convolutional layers, each of which have 64 filters of 3X3 dimension followed by another 2X2 maxpool layer and lastly passed to a convolutional layer having 128 filters of 3X3 dimension. Finally we are left with an output of shape: 8X8X128.
In one of our model we used a pre-trained VGG Model to extract feature from the Brain Activation MA
Results
We employed three models for the task of Word Familiarity, one in which we extract and train the entire convolutional neural network and the other in which we have used a pre-trained model VGG-Net16 to extract the features from a middle convolutional layer. Since our data is skewed towards the positive side we also calculate other performance metrics as well the results are provided in the following table.
Model
Accuracy
Precision
F1-Score
Trained CNN weight-Theta
0.72
0.75
0.875
Pre-Trained CNN weights
0.28
-
-
Trained CNN wigth Alpha+Theta
0.68
0.72
0.837
Discussion on Results
Seems like most of the information that is needed is contained in the theta frequency band which concurs with the results found in the other studies. Using of pre-trained weights from VGGNet16 was not at all effective and was rather conter-effective by decreasing the accuracy to 0.28. One of the reason for such a sudden drop must be the fact that VGGNet16 is trained on IMAGNET dataset which would have no resemblance to Brain Activation Maps. Other reason that I suspect could be that there is apparently no information that is stored in the time domain that could be actually be exploited using LSTMs.
Future Work
Currently we use a Unigram approach of understanding the word familiarity we aim to use N-grams in future for context based understanding; so as to see how a user interprets a word using its context.
Since the amount of data is less we propose to move our approach from Deep Learning to Statistical Machine Learning approach making use of HMMs and Probabilistic Graphical Model.